
In our continuing series on Design Techniques For Building Stateful Cloud-Native Applications (see Part 1, Part 2. and Part 3), we now take a look at message delivery, including some basic review of RPC, REST, Actors and more, as well as deliver mechanisms that make the most sense for reliability and how this applies to cloud-native design with Lightbend technologies to help you do it right the first time.
As software developers, we use our selected programming languages to run inline snippets of code that perform a series of computational steps that are interspersed with invocations of other modules. In object-oriented languages, objects invoke other methods in other objects. In functional languages, functions invoke other functions. In a way, this is a form of messaging: invoke a function, pass it a message via parameters, the function processes the request, and it returns a response message via the return values.
When we develop software for distributed systems, it would be desirable to continue to use method or function calls that reach across the network divide as simply as we make local calls. However, after decades of experience and numerous attempts to implement remote procedure calls we have learned that the dynamics of RPCs are considerably different from in-process method calls.
There is a massive difference between in-process procedure calls and remote procedure calls. With in-process method calls, everything happens within a single process on a single machine. An individual process is running, or it is not running. The procedure caller and the callee live together in an atomic processing universe. On the other hand, everything changes when the caller and the callee live in different processes connected across a distributed network.
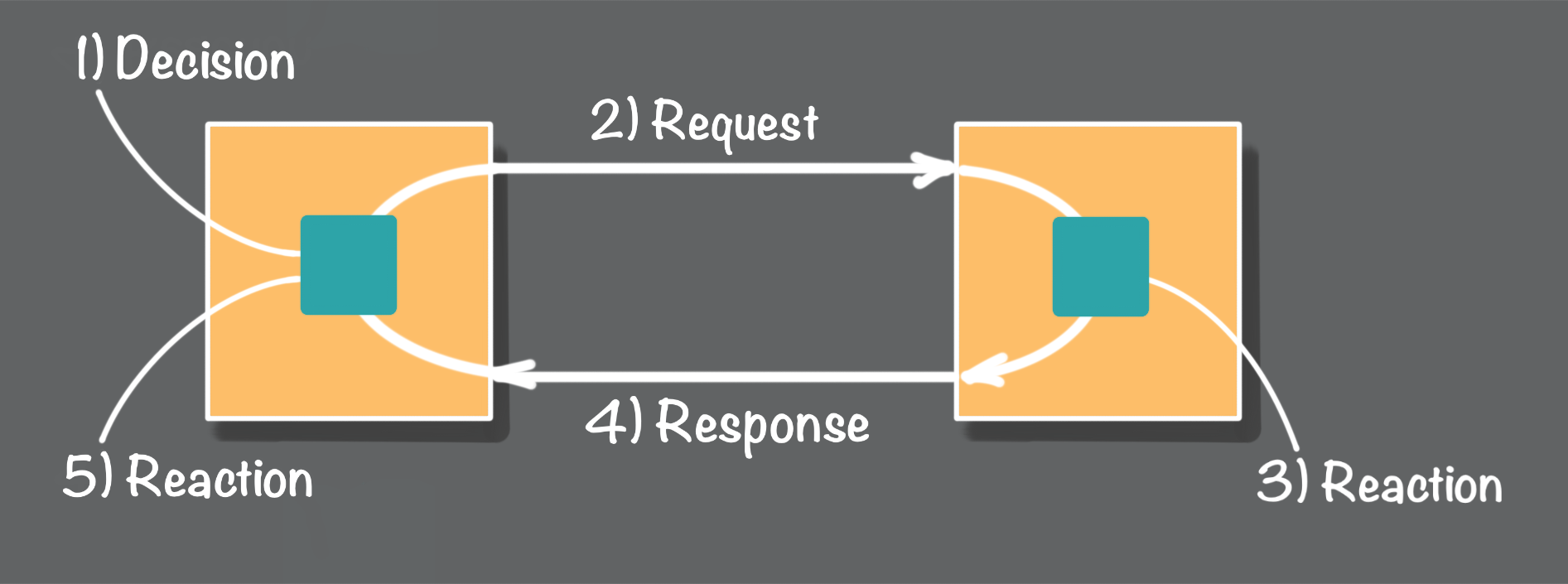
Looking at Figure 1 above, let's walk through an example to illustrate the distributed process. Starting with the process on the left, in Step 1 we need to ask the process on the right to perform an action. Next, in step 2, the left process sends a network request to the process in the right. In step 3, the process on the right receives the request, and it performs the requested action. Upon completing the requested action in step 4, the right side process returns a response. Finally, in step 5, the left side process receives the response.

While this may look like a method call, the difference is there are a lot of more things that will break (see Figure 2 above) when the caller and the callee are split across a network connection that can fail. The first problem is in step 2. Network issues may prevent the caller from sending requests to the callee. Next, the callee may be offline. Another failure scenario is that the callee received a request, processed it, but the callee is unable to return a response due to a network issue. Or in step 5 the request was sent, processed, but the caller is offline, which prevents the callee from returning a response.
So how do we get around these reliability challenges that are ever-present in distributed networks? When you implement various forms of messaging, it helps to categorize your implementation into one of three categories. The following category definitions are copies from the Akka Message Delivery Reliability documentation.
With these 3 categories you can identify if the messaging approach you are considering meets your requirements. Let's look at an example scenario to see how this works.
Say you are building a system of microservices. You have two services that interact with each other. In this case when service A processes a request, that triggers the need to notify service B that this has happened. For example, let's say that service A is an order service and service B is a shipping service.
What about using REST? Service A makes RESTful requests to service B. Which of the three categories is this? The RESTful approach is at-most-once, which means sometimes some messages will not be delivered. In this scenario, an at-most-once messaging implementation is not acceptable.
What about using a service bus? With a service bus, such as Apache Kafka or Apache Pulsar, now service A is a message publisher, and service B is a consumer. What category does this fall into? It looks like it provides at-least-once delivery, as once a message is published it will be delivered to the consumers; however, you need to look for any cracks in the implementation that message may fall through. For example, say service A receives a request, processes it and commits the order to a database, and then it makes a call to publish a message to the bus. Do you see the crack in this process? The crack is in between the completion of the DB transaction and the call to publish. Messages will be lost when failures occur in between these two steps.
These are solvable problems, but you need to be aware of the consequences of your implementation choices. In the next section, we look at methods for eliminating cracks in message flows.
Let's look at some of the techniques for eliminating failures and some approaches for gracefully handling broken message flows.
When messages cannot be delivered due to failures, the message sender may hang for a relatively long time until the request times out, or in some cases the caller may hang indefinitely. This type of problem often causes a log jam on hung requests. Worse, these log jams may overwhelm the calling process; for example, the calling process fails due to an out-of-memory error. The Circuit Breaker pattern is the most common solution used for handling this type of problem.

The general idea is a circuit breaker sits in between the message sender and the network interface. When a specified number of failures occur, the circuit breaker will move to an open state. In keeping with the taxonomy of actual circuit breakers, an open circuit breaker means that it's closed to incoming messages, ironically. So when a circuit breaker is open, all attempts to send more messages are immediately rejected. Also while in the open state, the circuit breaker attempts to occasionally to send a message; this is known as "half-open" state. If the message fails, the circuit breaker goes back into an open state. If the message is successfully delivered the circuit breaker goes back into a closed state, allowing regular message traffic once again.
For more details on this, see the Akka documentation or Martin Fowler, or take a look at the many other sources available on this topic.
When the requirement is that for a given message sender all messages must be delivered to a message receiver, it is necessary that the message delivery process uses either an at-least-once or exactly-once approach. The challenge is that for the message sender the process of sending a message is at least a two-step operation. The first step is to complete a requested action, such as a database transaction. The second step is to attempt to send a message. The fun part is when the second step, delivering the message, cannot be completed.

One approach that is used to ensure that all messages are delivered at-least-once is to use a retry loop (Figure 4 above). With the retry loop, the message sender will no give up until each message is delivered. When a message delivery attempt fails, the sender will try again. The sender will keep trying for a limited time and then give up, or it will keep trying indefinitely.
The fun part is that the retry process needs to be durable. That is, the retry process needs to be able to recover from a failure of the sending process. When the sending process fails and is restarted, to satisfy the at-least-once requirement the sending process needs to be able to recover the pending messages when the process is restarted after a failure.
Event Sourcing (ES) and Command Query Responsibility Segregation (CQRS) is a big topic. Here we are only going to focus on how ES & CQRS is used to facilitate at-least-once message delivery.

Event Sourcing uses an event store, which is an ideal persistent store for pending messages. One approach used is the message sending process is watching the event store (Figure 5 above). As events are written to the event store, the sending process reads these events and attempts to send the associated message. As messages are successfully sent, the sending process advances to the next event. The sending process needs to persist the current offset to the next event to be sent. With the persisted offset, the sending process is failure resistant.
Message-driven systems is one of the fundamental characteristics of Reactive Systems as defined in the Reactive Manifesto. The evolution of Reactive concepts were influenced by the evolution and the development of the Akka toolkit and Play Framework. Lagom Framework, which is a microservice framework built on top of Akka and Play, came along later. Each of these three Lightbend technologies share a message-driven heritage.
One of the many features of Akka is that it provides an implementation of the actor model. Actors are powerful building blocks based on a simple asynchronous messaging protocol. The only way to interact with an actor is to send it an asynchronous message. See the actor model Wikipedia page for a definition. And. of course, see the Akka documentation as well.
In Akka, actor messaging falls into the at-most-once category, which is similar to the previously discussed RESTful messaging. In some scenarios, at-most-once messaging is perfectly acceptable. However, there is a solution provided that supports at-least-once message delivery, see Akka persistence for more details on how this is done. The Akka toolkit aslo provides an implementation of circuit breakers.
Play Framework has extensive support for handing RESTful messaging. Other forms of messaging are typically handled using Akka with Play or using other libraries. For example, see the section of for handling requests, including suggestions for circuit breakers.
Lagom Framework supports both at-least-once messaging and at-most-once messaging. See the Lagom design philosophy section for a description of how Lagom fulfills the basic requirements of a Reactive Microservice. Also, see the documentation on Internal and external communication for more details on how Lagom provides support for a variety of message delivery implementations.
Implementing the right message delivery is fun. It is easy to build a leaky and brittle message delivery process, but fortunately, it is not that difficult to harden the process. The key concept is to think first about what your requirements are and identify how they fit into the three message delivery categories: at-most-once, at- least-once, or exactly-once. Another way to think of this is this, is it ok to occasionally drop messages or not?
It is relatively easy to implement a leaky message delivery process that sometimes drops messages, and this is perfectly acceptable in many applications. However, when your requirements demand that all messages must be delivered, you need to scrutinize closely every stage of the message journey to make sure that no messages can fall through a crack.
To learn more about stateful and stateless services for cloud-native services, check out this excellent white paper from our CTO, and the creator of Akka, Jonas Bonér, titled “How To Build Stateful, Cloud-Native Services With Akka And Kubernetes”. Read in HTML or download the PDF here:

